操作
click
示例:
input
示例:
scroll
示例:
scroll_to_bottom
示例:
wait
示例:
wait_for_element
示例:
fetch_resource
示例:
通用参数
适用于上述所有操作的参数type
timeout_s
wait_time_s
on_error
获取网络请求
如果网站通过获取JSON 对象来填充内容,您可以只抓取网络请求,从而避免处理 HTML。为此,您可以使用 fetch_resource 浏览器操作,如下所示。
例如,当加载 yahoo.com 并打开网络选项卡时,我们可以看到正在加载一个 exp.json 文件:
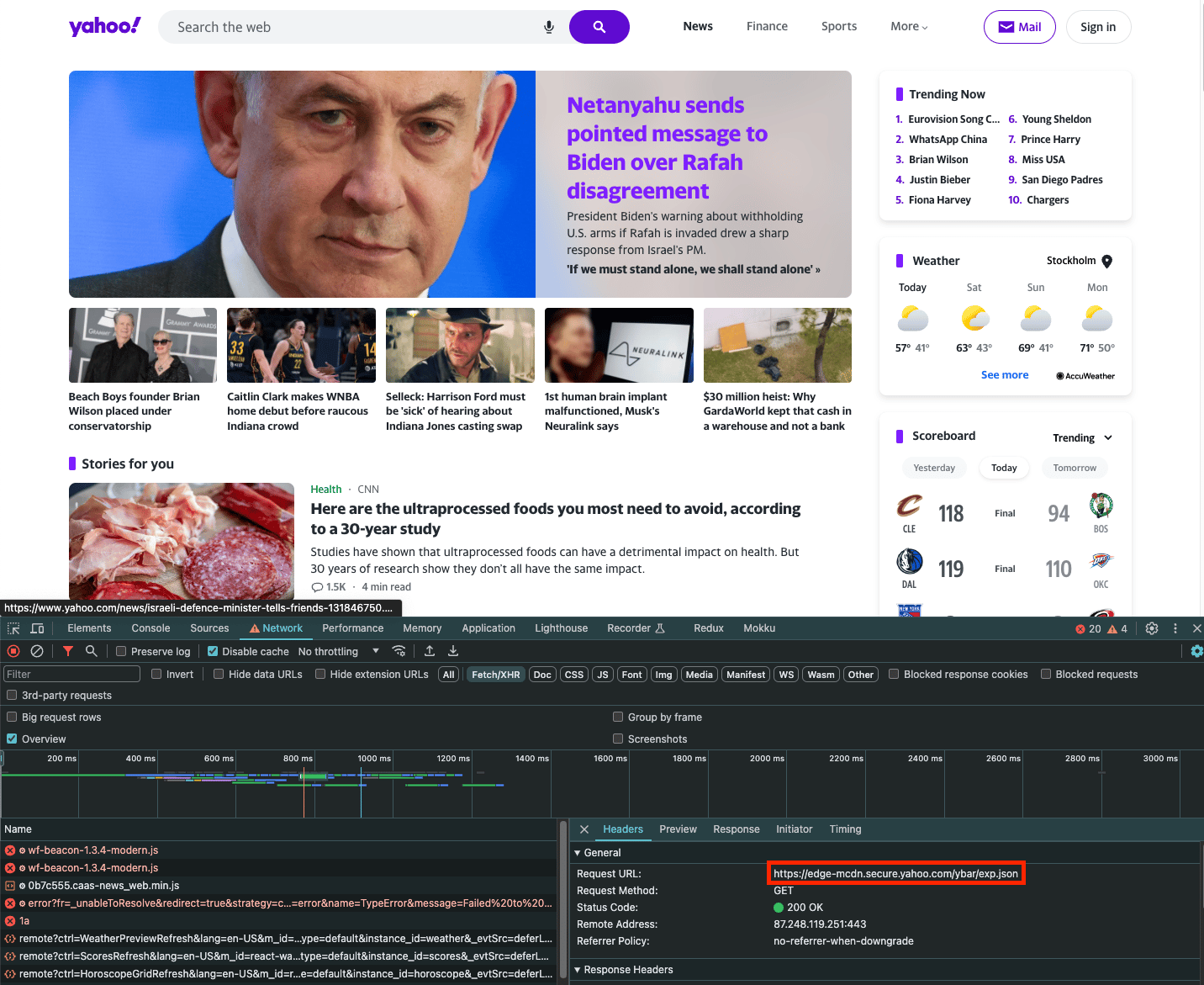
fetch_resource 浏览器操作。请注意,filter 是与文件名匹配的正则表达式:
支持
需要帮助或只是想打个招呼?我们的支持团队全天候为您服务。
您也可以随时通过电子邮件 support@decodo.com 联系我们。
您也可以随时通过电子邮件 support@decodo.com 联系我们。
反馈
找不到您要找的内容?请求一篇文章!
有反馈意见?分享您对我们如何改进的想法。
有反馈意见?分享您对我们如何改进的想法。