Core and Advanced plans are no longer available for purchase. Please consider migrating to the all-in-one Web Scraper API; check out the guide here.
Actions
click
Example:
input
Example:
scroll
Example:
scroll_to_bottom
Example:
wait
Example:
wait_for_element
Example:
fetch_resource
Example:
General Arguments
Arguments available for all actions abovetype
timeout_s
wait_time_s
on_error
Fetching a Network Request
If a website populates content by fetching aJSON object, you can scrape just the network request and thus avoid having to deal with HTML altogether. To do this, you can use the fetch_resource browser action, as shown below.
For example, when loading yahoo.com and opening the Network tab, we can see an exp.json file being loaded:
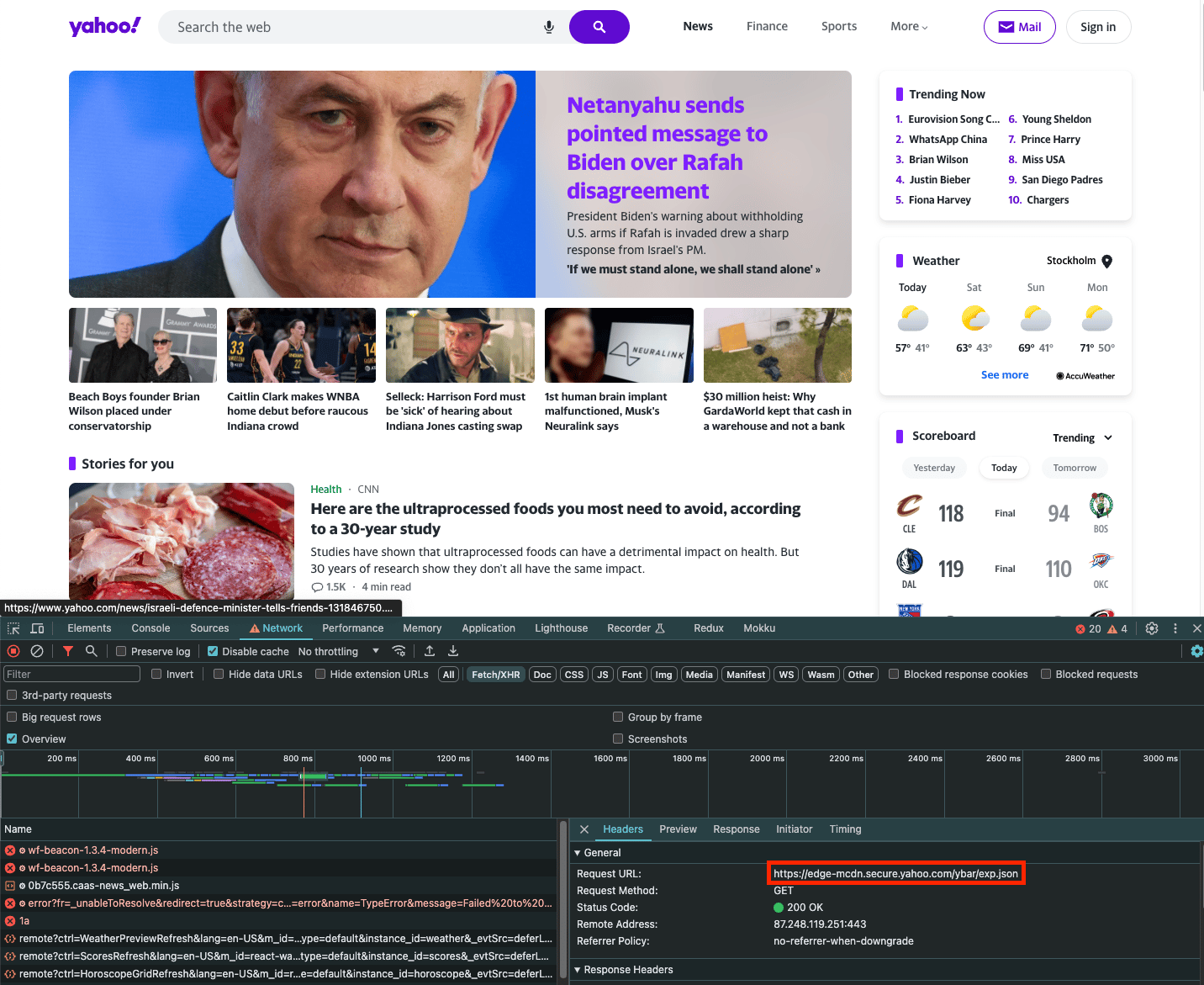
fetch_resource browser action. Note that filter is a regular expression that matches the filename:
Support
Need help or just want to say hello? Our support is available 24/7.
You can also reach us anytime via email at support@decodo.com.
You can also reach us anytime via email at support@decodo.com.
Feedback
Can’t find what you’re looking for? Request an article!
Have feedback? Share your thoughts on how we can improve.
Have feedback? Share your thoughts on how we can improve.