Video downloader
Download videos into your storage
Decodo Video downloader (target: youtube_video) can be used to download and save specified Youtube videos into the s3 compatible storage.
youtube_video
- The
youtube_videotarget only supports asynchronous and batch integrations.- Batch
youtube_videorequests are limited to 100 video per request.- Downloading is supported for videos of 3 hours or less.
- The download time is limited to 1 hour.
To get access or learn more, please Contact our sales team
Download a YouTube video into an Amazon S3-compatible storage location.
| Parameter | Type | Required | Description | Default | Example |
|---|---|---|---|---|---|
target | string | ✅ | Required to select YouTube download. | youtube_video | |
query | string | ✅ | YouTube video ID. | dFu9aKJoqGg | |
upload_url | string | ✅ | The URL to a S3-compatible storage location. | https://<key>:<secreat>@<bucket-url> | |
media | string | Select between video without sound, audio, or audio_video for both. | audio_video | ||
quality | string | Quality of video or audio. Valid options: best, worst, 480, 720, 1080, 1440, 2160. | 720 |
curl --request 'POST' \
--url 'https://scraper-api.decodo.com/v2/task' \
--header 'Accept: application/json' \
--header 'Authorization: Basic Authentication Token' \ // update with authentication token
--header 'Content-Type: application/json' \
--data '
{
"target": "youtube_video",
"query": "PFRn5zKJTD8",
"upload_url": "https://storage_username:[email protected]/video-folder"
}
'Delivery to S3
You can download videos straight into your S3 bucket by providing a number of arguments through the upload_url parameter. In the steps below, we will upload a sample video into a new bucket.
If you have the option, we recommend creating a new bucket for video downloads. That said, the following steps will also work on an existing bucket.
In order to start downloading videos:
-
Create a new S3 bucket with default setup and permissions.
-
Attach the
PutObjectpermission for your bucket on the IAM user:-
Add an inline policy:
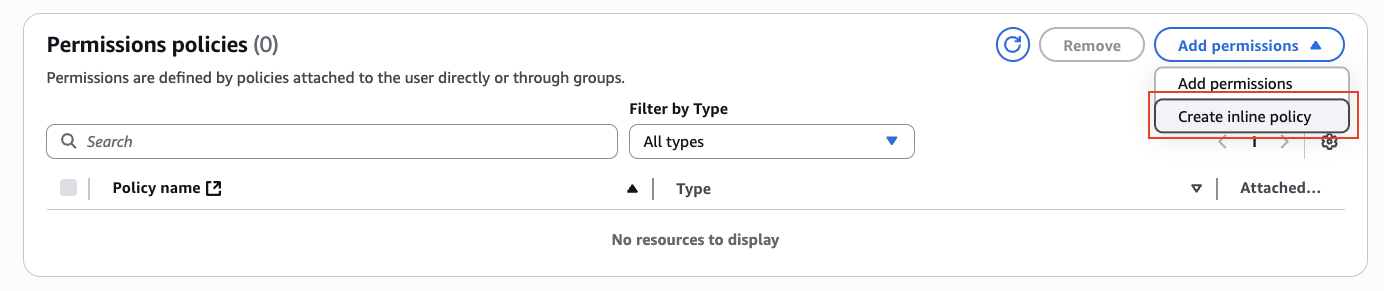
-
Under Service, select S3.
-
Under Actions:
- The following permissions need to be added to the bucket:
GetBucketLocation
- Thew following permissions need to be added to the folder of the bucket:
PutObjectPutObjectAcl
- The following permissions need to be added to the bucket:
-
Under Resources, select Specific, click on Add ARN, add your bucket name and your video folder name:
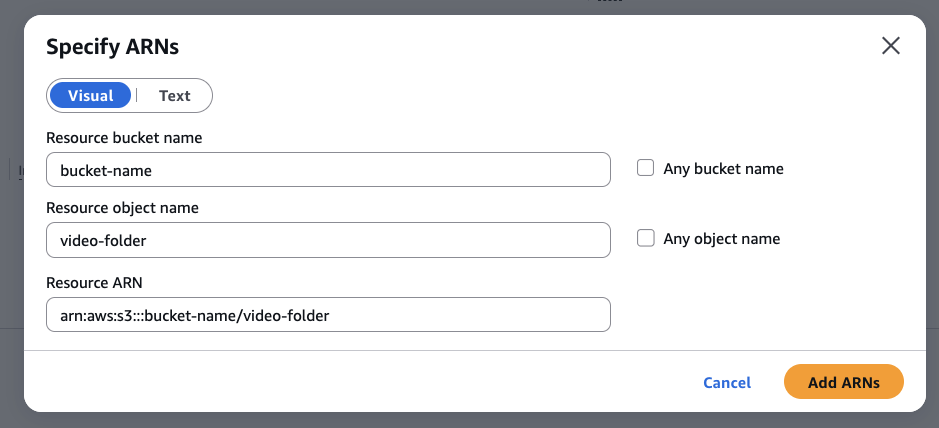
-
Your final policy statement should look like this:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Statement01", "Effect": "Allow", "Action": "s3:GetBucketLocation" "Resource": "arn:aws:s3:::your-bucket" }, { "Sid": "Statement02", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::your-bucket/*" } ] }
-
-
Generate an access key and secret for that user.
- When asked for use case, select Other.
The access key sent to Scraper API cannot include any non URI-escaped characters that may conflict with the
upload_urlparameter, such as/or@.If your key generated by AWS includes such characters, please regenerate your key.
-
Call Scraper API with the following sample parameters:
{
"target": "youtube_video",
"query": "PFRn5zKJTD8",
"upload_url": "https://access_key:[email protected]/video-folder"
}Things to note:
access_keyandaccess_secretare generated from step 4.us-west-2is used as a sample region, your AWS region may be different.- A
/video-foldermust be provided.
S3-compatible providers
Bellow are a number of S3-compatible providers that will also work with this target out of the box:
- MinIO
- Wasabi
- DigitalOcean Spaces
- Backblaze B2
- Scaleway Object Storage
- Linode Object Storage
- IBM Cloud Object Storage
- Oracle Cloud Object Storage
- Hetzner Cloud Storage
Sample request
curl --request 'POST' \
--url 'https://scraper-api.decodo.com/v2/task' \
--header 'Accept: application/json' \
--header 'Authorization: Basic Authentication Token' \ // update with authentication token
--header 'Content-Type: application/json' \
--data '
{
"target": "youtube_video",
"query": "PFRn5zKJTD8",
"upload_url": "https://storage_username:[email protected]/video-folder"
}
'A successfully queued job will return a response similar to this:
{
"target": "youtube_video",
"query": "PFRn5zKJTD8",
"page_from": 1,
"limit": 10,
"geo": null,
"device_type": "desktop",
"headless": null,
"parse": false,
"locale": null,
"domain": "com",
"output_schema": null,
"created_at": "2025-07-01 11:09:53",
"id": "7345770621134969857",
"status": "pending",
"content_encoding": "utf-8",
"updated_at": "2025-07-01 11:09:53",
"force_headers": false,
"force_cookies": false,
"headers_cookies_policy": false,
"media": "audio_video",
"quality": "720"
}Accessing geo-restricted videos
Scraper API attempts to automatically pick the best location from where to download geo-restricted videos. However, YouTube videos do not expose information about what geolocation a given video is restricted to, therefore, Scraper API may fail after a fixed number of attempts. Manually retrying the scraping request may be required.
Monitoring progress
The status of a queued video download can be checked through the /v2/task/:id/results endpoint (you can find id in the body of the response after the task has been created):
- HTTP status code
204indicates that the download is still processing. - HTTP status code
200indicates that the download has finished and an attempt to upload to your storage direction has been made.
Scraper API does not currently support:
- Showing download progress (completed/remaining percent)
- Indicating when uploading to
upload_urlfails (invalid credentials, bucket not found, etc.)Requests are still charged even if the upload to
upload_urlfails - we recommend testing with small videos first.
Support
Still can't find an answer? Want to say hi? We take pride in our 24/7 customer support. Alternatively, you can reach us via our support email at [email protected].
Updated 18 days ago